





How to handle Imbalanced Data?, What do datasets from industries like real-time marketing bidding, network intrusion detection, and fraud detection in banking have in common?
Less than 1% of infrequent but “interesting” events are frequently included in the data used in these fields (e.g. fraudsters using credit cards, users clicking advertisements,s or corrupted server scanning its network).
With imbalanced datasets, the majority of machine learning algorithms do not perform well. You can use the next seven methods to train a classifier to recognize aberrant classes.

Statistical test assumptions and requirements – Data Science Tutorials
1. Use the right evaluation metrics
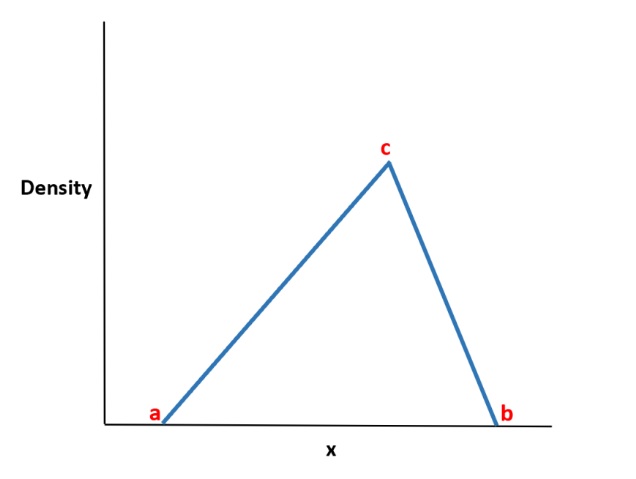
It can be harmful to use the wrong evaluation measures for a model that was created with unbalanced data. Imagine that the graph above represents our training data.
A model that labels all testing samples as “1” will have an outstanding accuracy (99%) if accuracy is used to gauge a model’s usefulness, but obviously, this model won’t offer us any useful information.
Alternative evaluation metrics that could be used in this situation include:
How many of the selected cases are relevant depends on precision and specificity.
Recall/Sensitivity: The proportion of relevant instances picked out.
The harmonic mean of recall and precision is the F1 score.
MCC stands for the correlation between the expected and observed binary classifications.
AUC: the correlation between the true-positive and false-positive rates.
Test for Normal Distribution in R-Quick Guide – Data Science Tutorials
2. Resample the training set
One can focus on collecting a different dataset in addition to applying various evaluation criteria. Under-sampling and over-sampling are two strategies to create a balanced dataset from an unbalanced one.
2.1. Under-sampling
By minimizing the size of the abundant class, undersampling evens out the dataset. When there is enough amount of data, this strategy is applied.
A balanced new dataset can be produced for further modeling by keeping all samples in the uncommon class and randomly choosing an equal number of samples in the plentiful class.
2.2. Over-sampling
On the other hand, undersampling is utilized when there is not enough data. By making unusual samples larger, it seeks to balance the dataset.
Instead of eliminating common samples, new rare samples are produced using techniques like repetition, bootstrapping, or SMOTE (Synthetic Minority Over-Sampling Technique)
Be aware that there is no certain benefit to one resampling technique over another. The use case and dataset each of these two methods apply to determine how they should be applied.
Additionally, a mix of over- and under-sampling frequently yields positive results.
How to compare variances in R – Data Science Tutorials
3. Use K-fold Cross-Validation in the Right Way
It is important to highlight that while utilizing the over-sampling method to handle imbalance issues, cross-validation should be correctly done.
Remember that over-sampling creates new random data based on a distribution function by using bootstrapping to create new random data from observed unusual samples.
If cross-validation is used following oversampling, we are essentially overfitting our model to a particular fake bootstrapping result.
Cross-validation should therefore always be performed before oversampling the data, just as feature selection should be put into practice.
Randomness can only be added to the dataset by repeatedly resampling the data, ensuring that there won’t be an overfitting issue.
Best Books on Data Science with Python – Data Science Tutorials
4. Ensemble Different Resampled Datasets
Adding extra data is the simplest technique to successfully generalize a model. The issue is that classifiers that come pre-built, such as logistic regression and random forest, frequently generalize by omitting the unusual class.
Building n models using all the data from the rare class and n different samples from the plentiful class is an easy best practice.
If you want to combine 10 models, you might keep, for instance, 1.000 instances of the uncommon class while randomly selecting 10,000 instances of the abundant class.
Simply divide the 10.000 examples into 10 equal portions and train 10 separate models.
If you have a lot of data, this method is easy to use and fully horizontally scalable because you can simply train and run your models on several cluster nodes.
Additionally, ensemble models frequently generalize more effectively, which makes this method simple to use.
5. Resample with Different Ratios
By experimenting with the ratio between the rare and the plentiful class, the preceding strategy can be improved.
The data and models that are employed strongly influence the ideal ratio. However, it is worthwhile to try ensemble-training alternative ratios rather than training every model with the same ratio.
A model with a rare: abundant ratio of 1:1 and another with a ratio of 1:3, or even 2:1, may make sense if ten models are trained. The weight that one class receives can vary depending on the model used.
Convert multiple columns into a single column-tidyr Part4 (datasciencetut.com)
6. Cluster the abundant class
Sergey suggested a sophisticated strategy on Quora. He advises clustering the abundant class in r groups, where r is the number of cases in r, rather than using random samples to cover the diversity of the training samples.
Only the medoid (cluster center) for each group is preserved. The model is then trained using only the medoids and members of the uncommon class.
7. Design Your Models
All of the earlier techniques preserve the models as a fixed element and center their attention on the data. However, if the model is appropriate for unbalanced data, there is no need to resample the data.
If the classes are not overly skewed, the well-known XGBoost is already an excellent place to start because it internally ensures that the bags it trains on are not unbalanced. However, the data is still resampled; it just takes place covertly.
It is easy to create several models that naturally generalize in favor of the rare class by creating a cost function that penalizes incorrect classifications of the rare class more severely than incorrect classifications of the plentiful class.
In order to penalize incorrect classifications of the rare class by the same ratio that this class is underrepresented, for instance, an SVM could be modified.
Two-Way ANOVA Example in R-Quick Guide – Data Science Tutorials
Summary
This is merely a place to get started when dealing with uneven data; it is not an exhaustive list of methods.
It is extremely advised to attempt several strategies and models in order to determine which ones perform best because there is no one approach or model that works best for all challenges. Be imaginative and combine various strategies.
It is also crucial to be aware that the “market rules” are continually evolving in several fields (such as fraud detection and real-time bidding), where unequal classes exist. Therefore, see whether any historical data may have been dated.