





How to compare the performance of different algorithms in R?, Installing and loading the microbenchmark package into R is the first step.
In addition, the ggplot2 package is used for visualization.
install.packages("microbenchmark")
library("microbenchmark")
install.packages("ggplot2")
library("ggplot2")
Example 1: Microbenchmark Options
We wish to examine the effectiveness of various methods for calculating the sum of a vector’s squared values using the microbenchmark program.
Free Best Online Course For Statistics – Data Science Tutorials
For that, we define two distinct functions.
Function f1 uses a loop.
f1 <- function (x) {
out <- 0
for (i in 1:length(x)) {
out <- out + x[i]^2
}
out
}
R’s ability to directly calculate the squared values of each element in a vector is used by function f2.
Rejection Region in Hypothesis Testing – Data Science Tutorials
f2 <- function (x) {
sum(x^2)
}
Now, we use rnorm to create a vector x with 1000 randomly chosen values from a normal distribution, and the microbenchmark function to assess how well f1 and f2 perform.
Both routines are run 100 (the default value) times by the microbenchmark.
set.seed(123) x <- rnorm(10000) mout <- microbenchmark(f1(x), f2(x)) mout
Unit: microseconds
expr min lq mean median uq max neval cld
f1(x) 364.0 372.10 564.827 382.20 467.35 14340.9 100 b
f2(x) 37.2 40.45 206.097 42.95 79.50 6384.4 100 a
The result displays a summary of the microsecond statistics from the 100 runs. As you can see, f2 is far faster than f1.
Change ggplot2 Theme Color in R- Data Science Tutorials
Let’s experiment with the microbenchmark package’s parameters. This time, we increase the default value of iterations from 100 to 1000.
m_out2 <- microbenchmark(f1(x), f2(x), times = 1000) m_out2
Unit: microseconds
expr min lq mean median uq max neval cld
f1(x) 365.1 387.2 467.0933 430.9 499.50 989.1 1000 b
f2(x) 18.9 41.4 91.8615 47.3 76.85 1785.8 1000 a
As you can see from the second microbenchmark output, Neval now accepts the value 1000.
Random Forest Machine Learning Introduction – Data Science Tutorials
Additionally, you can see that there was little change in the summary statistics, particularly the median and upper and lower quartiles.
Using ggplot, we can see how long the 1000 iterations of calculation took.
ggplot(m_out2, aes(x = time/1000, y = expr, color = expr)) + geom_violin() + geom_boxplot(width = 0.1) + scale_x_continuous(trans = 'log2')

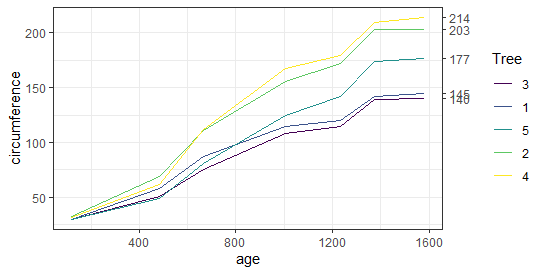
Figure 1 displays the results of the preceding R syntax; you can observe the distribution of calculation time by iteration and function.
How to add labels at the end of each line in ggplot2? (datasciencetut.com)